Learning To Poke by Poking:
Experiential Learning of Intuitive Physics
Pulkit Agrawal*, Ashvin Nair*, Pieter Abbeel, Jitendra Malik, Sergey Levine
- *Equal Contribution
Abstract
We investigate an experiential learning paradigm for acquiring an internal model of intuitive physics. Our model is evaluated on a real-world robotic manipulation task that requires displacing objects to target locations by poking. The robot gathered over 400 hours of experience by executing more than 50K pokes on different objects. We propose a novel approach based on deep neural networks for modeling the dynamics of robot’s interactions directly from images, by jointly estimating forward and inverse models of dynamics. The inverse model objective provides supervision to construct informative visual features, which the forward model can then predict and in turn regularize the feature space for the inverse model. The interplay between these two objectives creates useful, accurate models that can then be used for multi-step decision making. This formulation has the additional benefit that it is possible to learn forward models in an abstract feature space and thus alleviate the need of predicting pixels. Our experiments show that this joint modeling approach outperforms alternative methods. We also demonstrate that active data collection using the learned model further improves performance.
Paper
Preprint of the paper is available at: [pdf]
Data
Our data is released publicly here. An explanation of the format and instructions for using it are included as an iPython notebook.
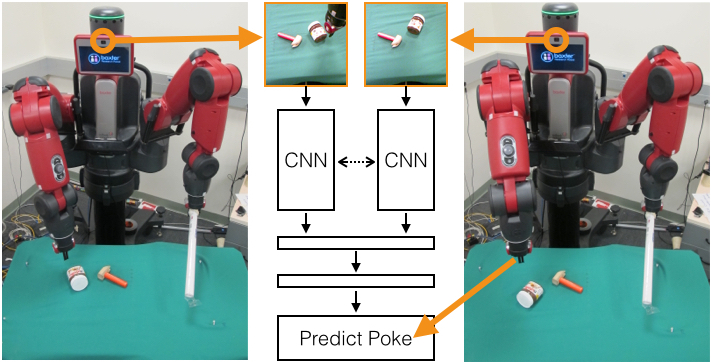
Data Collection
Unexpected Poking Dynamics
Modelling the effect of pokes on real world objects is not easy. The complex geometry and material properties of objects often leads to unexpected motion as shown in the following video clip.
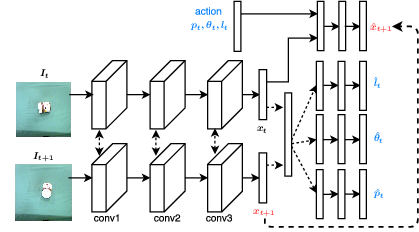
Our Model: Moving away from predicting pixels
|
We model the dynamics of robot’s interactions directly from images, by jointly estimating forward and inverse models of dynamics. The inverse model objective provides supervision to construct informative visual features, which the forward model can then predict and in turn regularize the feature space for the inverse model. The interplay between these two objectives creates useful, accurate models that can then be used for multi-step decision making. This formulation has the benefit that it is possible to learn forward models in an abstract feature space and thus alleviate the need of predicting pixels.
Model Performance
|
Our method is shown below, being used to poke objects into a target configuration. The model is trained on only image pairs that contain images one action away from each other. However, it is able to succesfully use the model to move objects farther away. |
|
The model is able to succesfully act on objects not included in its training set. |
|
The actions we execute are essentially greedy and there is no long term planning. Therefore, when presented with the situation below, the model does not try to move around the obstructing object. |
|
Every training pair the model sees is the result of one action, so multiple objects in different parts of the scene cannot move together. When faced with multiple objects to move to reach the target, the model sometimes succeeds but often gets stuck. |
Supplemental Materials
The robot is tasked with displacing the object from initial to target configuration. Using the multistep decision making proposed in the paper, the final result of the pokes is shown as the final state in the image below.
Additional supplemental materials detailing the simulation experiments will be released soon.
Code and Models
To be released soon.
Presentation
This work was an oral presentation at NIPS 2016. This link contains a recording of the presentation.
Big Data in Robotics
It's only very recently, that there is a growing interest in robotic learning from large amounts of interaction data. While the goal of our work is to learn intuitive models of physics for control, it's worth mentioning the following prior and contemporary works that have addressed other interesting learning problems from large scale robotic interaction data:
- Pinto, L., & Gupta, A., Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours, ICRA, 2016.
- Levine, S., Pastor, P., Krizhevsky, A., & Quillen, D., Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection, arXiv:1603.02199, 2016.
- Pinto, L., Gandhi, D., Han, Y., Park, Y. L., & Gupta, A., The Curious Robot: Learning Visual Representations via Physical Interactions, arXiv:1604.01360, 2016.
Acknowlegements
First and foremost, we thank Alyosha Efros for inspiration and fruitful discussions throughout this work. The title of this paper has been partly influenced by the term ``pokebot" that Alyosha has been using for several years. We would like to thank Ruzena Bajcsy for access to the Baxter robot and Shubham Tulsiani for helpful comments. This work was supported in part by ONR MURI N00014-14-1-0671 and ONR YIP. Sergey Levine was partially supported by ARL, through the MAST program. We gratefully acknowledge NVIDIA corporation for the donation of
K40 GPUs and access to the NVIDIA PSG cluster for this research.
Website Template
The template for this website has been adopted from Carl Doersch.
Contact
For comments/questions, contact Pulkit Agrawal